Version Database Changes With Liquibase
Contents
1 What Liquibase does
2 Liquibase core concepts
2.1 How database changes are represented
2.1.1 The changeset and changetype
2.1.2 Changeset uniqueness
2.1.3 The changelog
2.2 How database changes are managed
2.2.1 The DATABASECHANGELOG table
3 Using the Liquibase CLI
3.1 Setting up a directory
3.2 Liquibase commands
4 Summary of concepts
5 Integrating Liquibase
Picture this, you’re part of a a team of developers with a backend written in Java. You use Hibernate as your JPA provider (an ORM tool), which allows you to persist regular java classes to a database (a.k.a JPA entities). Whenever you start your application in your local environment you set Hibernate’s hibernate.hbm2ddl.auto property to update, which tells Hibernate to automatically read any new changes to an entity and update its schema accordingly.
As cool as this Hibernate feature is, using it in a production environment is not recommended. Therefore your team writes SQL scripts to track each change made to an entity, and all changes to the production database are released manually. These SQL scripts are organized by major release and are versioned along with the rest of the source code.
So why would your team consider working with a database versioning tool like Liquibase? The short answer: to reap many of the same benefits you get from using version control with your source code. In fact, some of the problems associated with the above SQL script setup are:
- There is no formal concept of unit of change to the database, it’s hard to delimit the scope of a change and infer its purpose.
- There is no obvious way to know which changes have already been applied to the database.
- There is no indication of who authored a change.
- Changes must be deployed manually every time.
Liquibase offers solutions to these types of problems, although note that there are other tools such as Flyway which offer similar solutions. In fact, the dev team at my company was in a similar situation and I was tasked with researching a better way to version and deploy changes to our database. In this post I will share with you some of the core concepts and benefits of using Liquibase.
What Liquibase does
Liquibase is a program that versions changes made to a database. It can be used via a variety of tools: CLI, API, Maven, Ant… (I will be focusing on a workflow using the CLI).
Here is an example of a basic workflow using Liquibase:
- Write database changes to a (version controlled) file (called a changelog in Liquibase, but I will explain this later).
- Run a
liquibase updatecommand from your terminal. - Liquibase will check which changes have already been applied to your database.
- Liquibase will apply only those changes which have not yet been applied.
This was a very cut and dry example of how Liquibase can be used. In the following section I will explain the Liquibase concepts behind these steps in greater detail, ending with a discussion regarding the integration of Liquibase in your development workflow.
Liquibase core concepts
How database changes are represented
The changeset and changetype
The fundamental atomic unit of change to a database in Liquibase is known as a changeset. A changeset is a change you want to make to the database (e.g. adding a column, creating a table, deleting a row…). A changeset is also what Liquibase keeps track of to determine what has changed in a database (similar to a commit in Git).
You can group more than one change in a changeset however it’s best practice for a changeset to correspond to a single logically coherent change to your database (again like a git commit, you don’t want to throw a bunch of changes in a changeset otherwise the purpose of that changeset will be less clear).
But what do you call all the changes that you can put in a changeset? Enter the changetype. Changesets are composed by one or more changetype(s), which describe the type of a change occurring in a changeset (see all available changetypes).
Example changeset that adds a column to a table:
<changeSet id="3" author="other.dev">
<addColumn tableName="person">
<column name="country" type="varchar(2)"/>
</addColumn>
</changeSet>The above changeset uses the addColumn changetype.
Changeset uniqueness
So now we know that a changeset is the basic unit of change in Liquibase. But if Liquibase is supposed to track and manage all our changesets (offering update and rollback commands…), how does it differentiate between changesets to tell them apart? What makes a changeset unique?
You may have noticed the id and author properties of the above changeset. In fact, a changeset is uniquely identified given an id, an author, and the filename of the changeset (all of which are used to generate an md5 checksum).
Note that the id property does not need to be a number, it could be a descriptive string (e.g. id="adding-person-column"). It’s a good idea to agree on certain conventions like this with your entire team so that you end up with consistently formatted and readable changesets. In my case I ended up writing up a small page of internal documentation, describing the way our team should approach writing changesets.
The changelog
We’ve got out changsets and changetypes, now when you write them, where do you put them? When you write a changeset, you’ll have it stored in a changelog, which is a file that groups together multiple changesets.
Changelogs can be written in XML, YAML, or JSON. The changetypes you will use in your changesets are database agnostic, meaning Liquibase will generate database specific SQL from your changelogs depending on which target database you’re telling liquibase to apply the changes to. You can inspect the SQL Liquibase will execute during a liquibase update with the following command:
liquibase updateSQLThis is extremely useful because it shows you exactly what Liquibase will execute on your database, so you can rest assured that you wrote your changesets correctly.
If need be, you also have the option of writing changelogs directly in SQL for database specific changes.
Usually best practice is to group changesets according to some logic, such as having each changelog correspond to a certain release version of your application. To do this note that you can insert changelogs in changelogs (e.g. using the insert tag). Good practice is to have one “master” changelog which references the other changelogs you wrote.
To recap, a changeset can include multiple changetypes (although fewer is better), and a changelog is made up of multiple changesets.
How database changes are managed
The DATABASECHANGELOG table
When you run the update command for the first time, Liquibase will create a DATABASECHANGELOG table for you. This table is the key to how Liquibase tracks which changes have already been applied to your database.
The DATABASECHANGELOG table will store all the changesets which have been applied in the order in which they were applied in. When you run the update command Liquibase applies your changesets in the order in which they appear in your changelogs.
When you perform an update, Liquibase will compare the changesets that are recorded in the DATABASECHANGELOG table with the current state of your changelogs, applying any changesets which have not yet been applied.
For example take the following changelog:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:pro="http://www.liquibase.org/xml/ns/pro"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.10.xsd
http://www.liquibase.org/xml/ns/pro http://www.liquibase.org/xml/ns/pro/liquibase-pro-3.10.xsd ">
<changeSet id="1" author="your.name">
<createTable tableName="person">
<column name="id" type="int">
<constraints primaryKey="true"/>
</column>
<column name="name" type="varchar(50)">
<constraints nullable="false"/>
</column>
<column name="address1" type="varchar(50)"/>
<column name="address2" type="varchar(50)"/>
<column name="city" type="varchar(30)"/>
</createTable>
</changeSet>
<changeSet id="2" author="your.name">
<createTable tableName="company">
<column name="id" type="int">
<constraints primaryKey="true"/>
</column>
<column name="name" type="varchar(50)">
<constraints nullable="false"/>
</column>
<column name="address1" type="varchar(50)"/>
<column name="address2" type="varchar(50)"/>
<column name="city" type="varchar(30)"/>
</createTable>
</changeSet>
<changeSet id="3" author="other.dev">
<addColumn tableName="person">
<column name="country" type="varchar(2)"/>
</addColumn>
</changeSet>
</databaseChangeLog>The above changelog would result in the following DATABASECHANGELOG table (if you haven’t already applied these changesets):

Notice how the order of the rows in the table above matches the order of the changesets in the changelog!
Also note that if you were to insert a changeset with id="4" between the 2nd and 3rd changesets above, the new 4th changeset would be appended to the table as if you had appended it at the end of the changelog file.
Liquibase also has a DATABASECHANGELOGLOCK table to prevent conflicts in case multiple instances of Liquibase are run on the same database.
Using the Liquibase CLI
Setting up a directory
There are many ways to use Liquibase, but to explain the basics of what is needed to run the tool I will take as an example a developer that wants to run Liquibase using the CLI.
To use the Liquibase CLI you will need to create a directory with two important files:
- A
liquibase.propertiesfile. - A changelog.
All Liquibase commands you run in this directory will read from the properties file. The changelog file must be referenced in the properties file so that Liquibase knows which changesets to apply.
As already mentioned, the command you will be using to apply your changesets is:
liquibase updateLiquibase commands
Liquibase offers some useful commands to ease the development process (see all commands). For example, as already mentioned, you can tell liquibase to show you the SQL that will be applied to your database given some changesets you just wrote.
You can also rollback changesets which have been applied in various ways (by count, by date, by label…)
If you’re interested in trying out Liquibase you can checkout the official Liquibase tutorial for beginners (the tutorial will have you using the Liquibase CLI).
Summary of concepts
To summarize the above discussion. Liquibase is a database versioning program which given a set of changelogs, applies your changesets to a database and keeps track of them in a DATABASECHANGELOG table.
The key Liquibase concepts to takeaway are:
- The changeset.
- The changetype
- The changelog
- The
DATABASECHANGELOGtable.
Here is a diagram representing a simple workflow using Liquibase with the concepts introduced throughout this post:
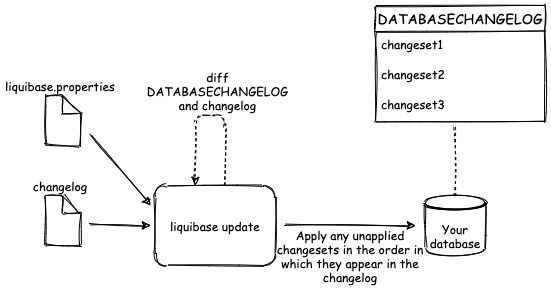
Integrating Liquibase
Learning how to use Liquibase is simple, the more challenging aspect is how to approach integrating it if you already have an established software product in production. Thankfully Liquibase is flexible from this point of view, as there are a variety of ways to integrate it and start using it.
In general, there are two main approaches to deploying changes to a database, you can either:
- Compare the current state of the database with a desired state and use Liquibase to generate a changelog with the changes you need to get to the desired state (state-based database deployment).
- Declare the changes you want to apply to a database and only apply those specific changes (migration-based database deployment).
You can read more about state-based vs. migration-based database deployment.
If you’re a new team without an established product you can simply start using the migration-based approach.
If your team already manages a product you could consider starting by generating a changelog which contains all changes needed to match the current state of your database.
My team already has an established product and we found it easier to begin using Liquibase starting from a major release, directly using the migration-based approach (this is also how Liquibase is primarily intended to be used).
I recommend starting by using Liquibase experimentally at first to see how the tool feels. Gradually you can then fully switch over once you find the most comfortable way to integrate it in you development process.